DBWeb2007はなかなか面白そうだ.
お金はあるし,火曜水曜は暇なんだから,行けば良かったなぁって,ちょっと後悔.
参加できなかったので,イベント記事からちょこちょこと.
やっぱりね.
Google先生がスゴイのは間違いないんだけど,凄すぎて困るわけだね.
それは往々にして,情報が多すぎるとか,UIの問題とか,クエリが悪いとか・・・
情報検索(じょうほうけんさく)とは、コンピュータを用いて大量のデータ群から目的に合致したデータを取り出すための技術。検索の対象となるデータには文書や画像、音声、映像、その他さまざまなメディアやその組み合わせとして記録されたデータなどが含まれる。
情報検索 - Wikipedia
情報検索は膨大なデータ群から目的の何かを探し出すことだ.
これは別エントリーで改めて書くが,膨大なデータ群が存在しているのが今のウェブ.
そして,Google先生はその膨大なデータ群を縦横無尽に検索する.
検索するのだから,目的の情報が見つかるはずなのに,見つからないのが現状.
それはどの問題か.
素となるデータ群が悪いのか,Google検索エンジンが悪いのか.
情報検索は膨大なデータ群から目的の何かを探し出すことだ.
何度も述べているが,「パタパタすると絵が変わるアレ」.
みんなが見たことあるし,膨大なデータ群にも格納されているだろうが,見つからない.
見つけられない.
何故か.
どうやって探せばいいか分からないからだ.
クエリを生成できなければ,検索できないのが現状.
どうやればイメージで検索することができるようになるのだろうか.
これに対する1つの解法がタギングだと思われるが,困難を極める.
未だに実用の域には達していないのではないだろうか.
そもそも,イメージであるにもかかわらず,言語の壁を越えられていない.
閑話休題.
UIの問題についての解法も様々なアプローチで研究されている.
「次世代検索は“人”を中心にしたものになるのではないか」と語る中村氏は、アノテーションに基づく検索結果の再ランキングや、ユーザーの行動に基づく集合的アノテーションをランキングに反映する研究をしている(注:アノテーションは英語で注釈のことだが、ここではユーザーが加えるタグや追加情報のこと)。根底にある問題意識は現在の検索サービスの制約だ。「例えば、東京、ホテルで検索すると200万件近いリンクが出るが実際にユーザーが見るのは上位5~10件。これはUIが困難であるのが問題。また、SEO対策のために精度も高くない」(中村氏)。
どうにもあっちこっちで見かける研究はアノテーションも然りだが,パーソナライゼーションが多い.
パーソナライズの場合,他人に影響されないので,SEOスパムのようなスパム攻撃を受けない.
そう言った意味では,スパムの影響を受けないので,ランキングは良いところに落ちるのかもしれない.
中村氏は、利用者自身によるアノテーションだけでなく、集合的アノテーションを取り入れた検索サービス「SBSearch」にも取り組む。SBSearchでは、既存のソーシャルブックマークでのブックマーク数やキーワードをランキングに反映させたり、ある一時期にネット上で話題になったページを重視するのか、逆に長期間にわたって一定の話題を集めているページを重視するのなどをユーザーは選べる。こうすることで「150~200位のページを手軽に上位に上げられる」(中村氏)
(中略)
ソーシャルブックマークサービスでは、内容を示す“内容タグ”(例:IT、Web、ソーシャル、検索)と“印象タグ”(例:おもしろい、これはすごい、便利)があるといい、印象タグを生かすことで「コンテンツ自体に含まれていない語彙で検索結果をフィルタ」できるのだという。
この方法は運用の仕方では危ない.
ソーシャルブクマスパムによる攻撃を受けることがある.
SBMスパムは次世代SEOと呼ばれており,SEO効果があるからこそ行われていると思う.
Googleの検索結果から不必要に強調されているSEO対策済サイトをノイズとして扱い,
如何にしてS/N比を上げていくかがこれらの研究の目的であろうから,SBMに頼るのは危ないかもしれない.
IPSJ69で発表した「タグクラウドのアレ」についても,スパム攻撃によってノイズが増える可能性がある.
可能性はあるが,情報源としてSBMだけを拠所にしているわけではないので,
S/N比を保つためなら,SBMの影響度を下げたり,無視したししても良いかもしれない.
話が少し逸れてしまったが,書きたいことはSBMスパムの話ではない.
次世代検索のメインストリームはランキングの改善なのだろうか.
Googleが付けたランキングを付け直すということは,言い換えれば,
ネット上の膨大なデータ群のサブセットであるGoogleの検索結果データ群を利用したランキング付けに他ならない.
ここに疑問を呈したい.
何故ランキングを付け直す必要があるのか.
それは簡単なことであって,
例えば、東京、ホテルで検索すると200万件近いリンクが出るが実際にユーザーが見るのは上位5~10件
という理由に起因する.
では,何故上位5件程度しか見られないかだ.
それはUIの問題である.
具体的に何か.
ブラウザをスクロールしなくても見える範囲が5件程度なんだ.
ただそれだけの理由なんだ.
だから,結局の所,ランキング付けを変更するならば,重要な情報が上位5件程度に現れないといけない.
そうでなくては,どんなにランキングが改善されていようが,意味を成さないのだ.
それが可能かどうかはよく分からないけど,可能であると信じたい.
ところで,こういったアプローチはレコメンデーションに近いと思う.
パーソナライゼーションはレコメンデーションにも近い(と思うんだけど,違うかな?).
オレはあんまりレコメンデーションというものを信じていなくて,自分の情報探索力を信じてる.
Amazon.jpが「あわせて買いたい」とか「こんな商品も買ってます」とか,余計なお世話だと思っている.
今まで,レコメンデーションを通じて購入したことは1度もない.
これでも,Amazonのマイストアにはかなり貢献し,ランク付けも「持ってる/持ってない」もしっかり評価している.
にも関わらず,今までオレに有益な情報をプッシュしてきたことは一度たりともない.
レコメンデーションって,実は幻想なんじゃないかとすら疑い始めている.
だからこそ,オレは検索結果のランキングだって,信じてない.
検索結果のランキングには明確な指標がない.
売上ランキングなら,売上という指標があるが,検索結果の指標はなんだろうか.
適合度という指標があるかもしれないが,その根拠もよく分からない.
どんどん話がずれていってしまっているのだが・・・
完結に述べますと,検索結果はカオスである必要があるんだと思うんです.
整然とした結果が出てくるから,上位5件程度しか眺めてもらえないんだと思う.
何かの書類を探すとき,机の上を引っかき回すように探すはずだ.
カオスであればあるほど,頑張って探すはずだ.
だから,多くの検索結果が1画面に収まっている状態はカオスだし,歓迎されるべきではないか.
そう考えるオレは,タグクラウドなアプローチを展開したのだ.
オレはあのカオスさがUI的に優れていると信じて疑わないのだが,如何だろうか.
まとめ:
ランキング方式は好きじゃないです.
スパム対策でS/N比が下がってしまいそうで,安心できません.
そもそもSEOスパム等が混在していることを前提に,カオスな状態にしておく方が現状を表していそう.
スパマーだって,そこに効果があるからスパムするわけで,
カオスな状態の中でスパムはどれ程の効果を発揮することができるのだろうか.
だから,検索結果のUIとしてはタグクラウドでもいいし,なんでもいいけど,カオスにしたい.
そう思います.
参考:
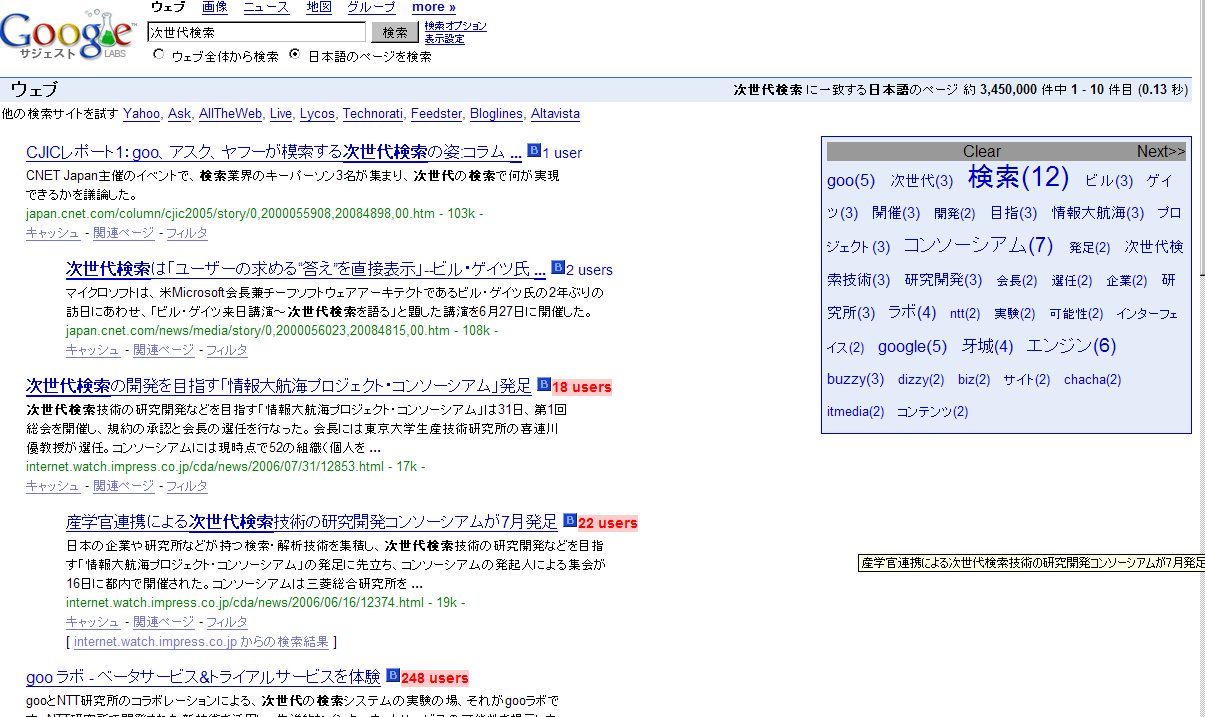
カスタマイズされまくったオレ仕様のFirefoxPEによる「次世代検索」のGoogle検索結果.
検索結果の横に,はてなブックマーク数が表示されるようにしてある.
これはこれで,人気があるサイトを見つけるのに役立つ.
右にはタグクラウドが表示されるようになっており,絞り込む際の手助けになる.
検索エンジンにはオレが何を探したいかなんて分かっていないんだから,
タグクラウドのように候補をいっぱい出してくれると,「あーこれこれ」って絞り込めて楽ちん.
・Googleの検索結果にSBM数を表示するGreasemonkey
・Googleの検索結果からタグクラウドを作成するGreasemonkey